Distributed Training in PyG
Warning
torch_geometric.distributed has been deprecated and will no longer be maintained.
For distributed training with cuGraph, refer to cuGraph examples.

Note
We are thrilled to announce the first in-house distributed training solution for PyG via torch_geometric.distributed, available from version 2.5 onwards.
Developers and researchers can now take full advantage of distributed training on large-scale datasets which cannot be fully loaded in memory of one machine at the same time.
This implementation doesn’t require any additional packages to be installed on top of the default PyG stack.
In real life applications, graphs often consists of billions of nodes that cannot fit into a single system memory. This is when distributed training of Graph Neural Networks comes in handy. By allocating a number of partitions of the large graph into a cluster of CPUs, one can deploy synchronized model training on the whole dataset at once by making use of PyTorch’s Distributed Data Parallel (DDP) capabilities. This architecture seamlessly distributes training of Graph Neural Networks across multiple nodes via Remote Procedure Calls (RPCs) for efficient sampling and retrieval of non-local features with traditional DDP for model training. This new technique in PyG was produced by engineers from Intel and Kumo AI.
Key Advantages
Balanced graph partitioning via METIS ensures minimal communication overhead when sampling subgraphs across compute nodes.
Utilizing DDP for model training in conjunction with RPC for remote sampling and feature fetching routines (with TCP/IP protocol and gloo communication backend) allows for data parallelism with distinct data partitions at each node.
The implementation via custom
GraphStoreandFeatureStoreAPIs provides a flexible and tailored interface for distributing large graph structure information and feature storage.Distributed neighbor sampling is capable of sampling in both local and remote partitions through RPC communication channels. All advanced functionality of single-node sampling are also applicable for distributed training, e.g., heterogeneous sampling, link-level sampling, temporal sampling, etc.
Distributed data loaders offer a high-level abstraction for managing sampler processes, ensuring simplicity and seamless integration with standard PyG data loaders.
Incorporating the Python asyncio library for asynchronous processing on top of PyTorch-based RPCs further enhances the system’s responsiveness and overall performance.
Architecture Components
Note
The purpose of this tutorial is to guide you through the most important steps of deploying distributed training applications in PyG. For code examples, please refer to examples/distributed/pyg.
Overall, torch_geometric.distributed is divided into the following components:
Partitonerpartitions the graph into multiple parts, such that each node only needs to load its local data in memory.LocalGraphStoreandLocalFeatureStorestore the graph topology and features per partition, respectively. In addition, they maintain a mapping between local and global IDs for efficient assignment of nodes and feature lookup.DistNeighborSamplerimplements the distributed sampling algorithm, which includes local+remote sampling and the final merge between local/remote sampling results based on PyTorch’s RPC mechanisms.DistNeighborLoadermanages the distributed neighbor sampling and feature fetching processes via multiple RPC workers. Finally, it takes care to form sampled nodes, edges, and their features into the classic PyG data format.
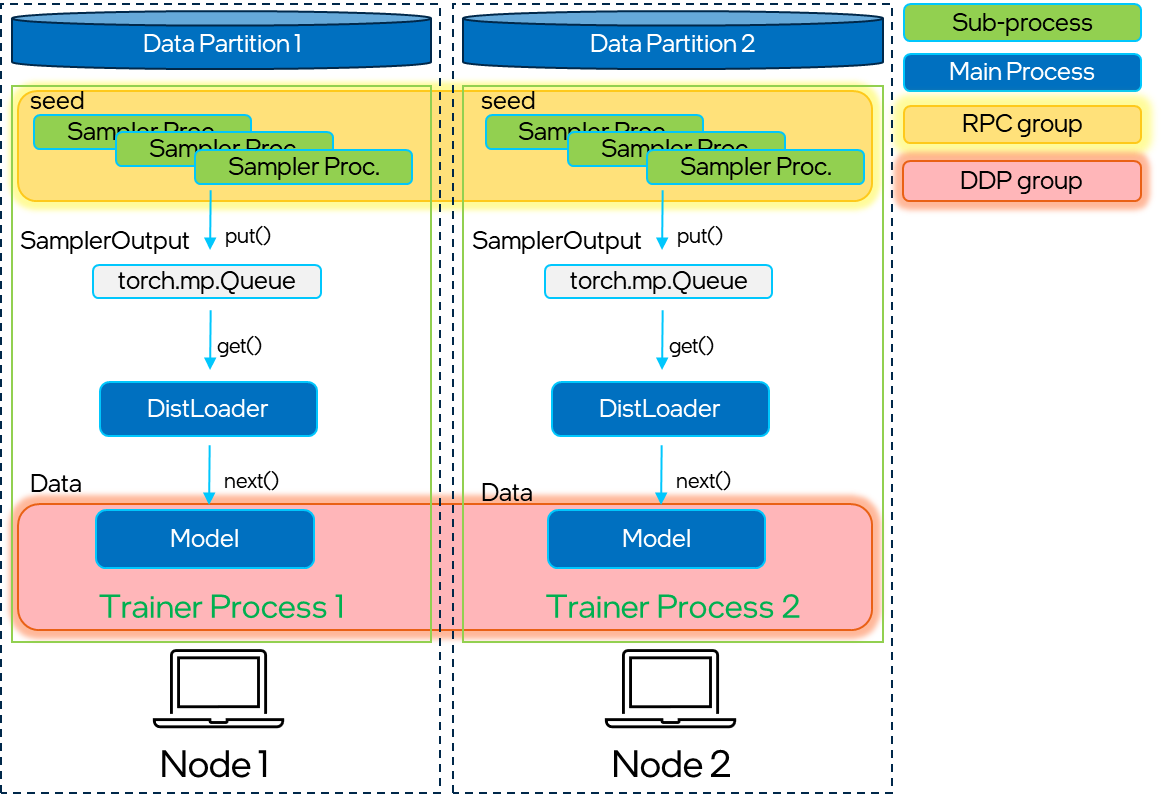
Schematic breakdown of the main components of torch_geometric.distributed.
Graph Partitioning
The first step for distributed training is to split the graph into multiple smaller portions, which can then be loaded locally into nodes of the cluster.
Partitioning is built on top of pyg-lib’s implementation of the METIS algorithm, suitable to perform graph partitioning efficiently, even on large-scale graphs.
Note that METIS requires undirected, homogeneous graphs as input.
Partitoner performs necessary processing steps to partition heterogeneous data objects with correct distribution and indexing.
By default, METIS tries to balance the number of nodes of each type in each partition while minimizing the number of edges between partitions. This ensures that the resulting partitions provide maximal local access of neighbors, enabling samplers to perform local computations without the need for communication between different compute nodes. Through this partitioning approach, every node receives a distinct assignment, while “halo nodes” (1-hop neighbors that fall into a different partition) are replicated. Halo nodes ensure that neighbor sampling for a single node in a single layer stays purely local.
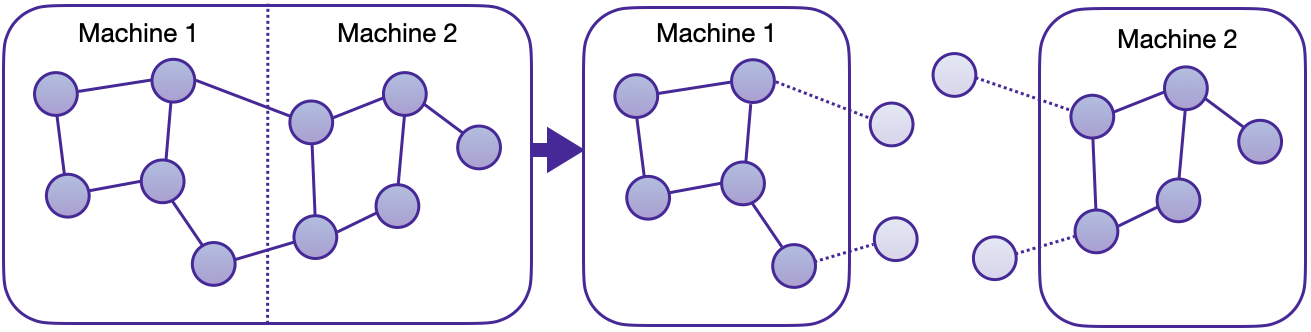
Graph partitioning with halo nodes.
In our distributed training example, we prepared the partition_graph.py script to demonstrate how to apply partitioning on a selected subset of both homogeneous and heterogeneous graphs.
The Partitioner can also preserve node features, edge features, and any temporal attributes at the level of nodes and edges.
Later on, each node in the cluster then owns a single partition of this graph.
Warning
Partitioning via METIS is non-deterministic and as such may differ between iterations. However, all compute nodes should access the same partition data. Therefore, generate the partitions on one node and copy the data to all members of the cluster, or place the folder into a shared location.
The resulting structure of partitioning for a two-part split on the homogeneous ogbn-products is shown below:
partitions
└─ obgn-products
├─ ogbn-products-partitions
│ ├─ part_0
│ ├─ part_1
│ ├─ META.json
│ ├─ node_map.pt
│ └─ edge_map.pt
├─ ogbn-products-label
│ └─ label.pt
├─ ogbn-products-test-partitions
│ ├─ partition0.pt
│ └─ partition1.pt
└─ ogbn-products-train-partitions
├─ partition0.pt
└─ partition1.pt
Distributed Data Storage
To maintain distributed data partitions, we utilize instantiations of PyG’s GraphStore and FeatureStore remote interfaces.
Together with an integrated API for sending and receiving RPC requests, they provide a powerful tool for inter-connected distributed data storage.
Both stores can be filled with data in a number of ways, e.g., from Data and HeteroData objects or initialized directly from generated partition files.
LocalGraphStore is a class designed to act as a container for graph topology information.
It holds the edge indices that define relationships between nodes in a graph.
It offers methods that provide mapping information for nodes and edges to individual partitions and support both homogeneous and heterogeneous data formats.
Key Features:
It only stores information about local graph connections and its halo nodes within a partition.
Remote connectivity: The affiliation information of individual nodes and edges to partitions (both local and global) can be retrieved through node and edge “partition books”, i.e. mappings of partition IDs to global node/edge IDs.
It maintains global identifiers for nodes and edges, allowing for consistent mapping across partitions.
LocalFeatureStore is a class that serves as both a node-level and edge-level feature storage.
It provides efficient put and get routines for attribute retrieval for both local and remote node/edge IDs.
The LocalFeatureStore is responsible for retrieving and updating features across different partitions and machines during the training process.
Key Features:
It provides functionalities for storing, retrieving, and distributing node and edge features. Within the managed partition of a machine, node and edge features are stored locally.
Remote feature lookup: It implements mechanisms for looking up features in both local and remote nodes during distributed training processes through RPC requests. The class is designed to work seamlessly in distributed training scenarios, allowing for efficient feature handling across partitions.
It maintains global identifiers for nodes and edges, allowing for consistent mapping across partitions.
Below is an example of how LocalFeatureStore is used internally to retrieve both local+remote features:
import torch
from torch_geometric.distributed import LocalFeatureStore
from torch_geometric.distributed.event_loop import to_asyncio_future
feature_store = LocalFeatureStore(...)
async def get_node_features():
# Create a `LocalFeatureStore` instance:
# Retrieve node features for specific node IDs:
node_id = torch.tensor([1])
future = feature_store.lookup_features(node_id)
return await to_asyncio_future(future)
Distributed Neighbor Sampling
DistNeighborSampler is a class designed for efficient distributed training of Graph Neural Networks.
It addresses the challenges of sampling neighbors in a distributed environment, whereby graph data is partitioned across multiple machines or devices.
The sampler ensures that GNNs can effectively learn from large-scale graphs, maintaining scalability and performance.
Asynchronous Neighbor Sampling and Feature Collection:
Distributed neighbor sampling is implemented using asynchronous torch.distributed.rpc calls.
It allows machines to independently sample neighbors without strict synchronization.
Each machine autonomously selects neighbors from its local graph partition, without waiting for others to complete their sampling processes.
This approach enhances parallelism, as machines can progress asynchronously, and leads to faster training.
In addition to asynchronous sampling, distributed neighbor sampling also provides asynchronous feature collection.
Customizable Sampling Strategies:
Users can customize neighbor sampling strategies based on their specific requirements.
The DistNeighborSampler class provides full flexibility in defining sampling techniques, such as:
Node sampling vs. edge sampling
Homogeneous vs. heterogeneous sampling
Temporal sampling vs. static sampling
Distributed Neighbor Sampling Workflow:
A batch of seed nodes follows three main steps before it is made available for the model’s forward() pass by the data loader:
Distributed node sampling: While the underlying principles of neighbor sampling holds for the distributed case as well, the implementation slightly diverges from single-machine sampling. In distributed training, seed nodes can belong to different partitions, leading to simultaneous sampling on multiple machines for a single batch. Consequently, synchronization of sampling results across machines is necessary to obtain seed nodes for the subsequent layer, requiring modifications to the basic algorithm. For nodes within a local partition, the sampling occurs on the local machine. Conversely, for nodes associated with a remote partition, the neighbor sampling is conducted on the machine responsible for storing the respective partition. Sampling then happens layer-wise, where sampled nodes act as seed nodes in follow-up layers.
Distributed feature lookup: Each partition stores an array of features of nodes and edges that are within that partition. Consequently, if the output of a sampler on a specific machine includes sampled nodes or edges which do not pertain in its partition, the machine initiates an RPC request to a remote server which these nodes (or edges) belong to.
Data conversion: Based on the sampler output and the acquired node (or edge) features, a PyG
DataorHeteroDataobject is created. This object forms a batch used in subsequent computational operations of the model.
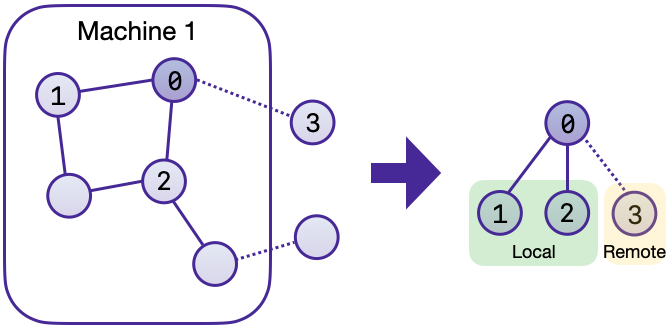
Local and remote neighbor sampling.
Distributed Data Loading
Distributed data loaders such as DistNeighborLoader and DistLinkNeighborLoader provide a simple API for the sampling engine described above because they entirely wrap initialization and cleanup of sampler processes internally.
Notably, the distributed data loaders inherit from the standard PyG single-node NodeLoader and LinkLoader loaders, making their application inside training scripts nearly identically.
Batch generation is slightly different from the single-node case in that the step of (local+remote) feature fetching happens within the sampler, rather than encapsulated into two separate steps (sampling->feature fetching).
This allows limiting the amount of RPCs.
Due to the asynchronous processing between all sampler sub-processes, the samplers then return their output to a torch.multiprocessing.Queue.
Setting up Communication using DDP & RPC
In this distributed training implementation two torch.distributed communication technologies are used:
torch.distributed.rpcfor remote sampling calls and distributed feature retrievaltorch.distributed.ddpfor data parallel model training
Our solution opts for torch.distributed.rpc over alternatives such as gRPC because PyTorch RPC inherently comprehends tensor-type data.
Unlike other RPC methods, which require the serialization or digitization of JSON or other user data into tensor types, using this method helps avoid additional serialization and digitization overhead.
The DDP group is initialzied in a standard way in the main training script:
torch.distributed.init_process_group(
backend='gloo',
rank=current_ctx.rank,
world_size=current_ctx.world_size,
init_method=f'tcp://{master_addr}:{ddp_port}',
)
Note
For CPU-based sampling we recommended the gloo communication backend.
RPC group initialization is more complicated because it happens in each sampler subprocess, which is achieved via the worker_init_fn() of the data loader, which is called by PyTorch directly at the initialization step of worker processes.
This function first defines a distributed context for each worker and assigns it a group and rank, subsequently initializes its own distributed neighbor sampler, and finally registers a new member in the RPC group.
This RPC connection remains open as long as the subprocess exists.
Additionally, we opted for the atexit module to register additional cleanup behaviors that are triggered when the process is terminated.
Results and Performance
We collected the benchmarking results on PyTorch 2.1 using the system configuration at the bottom of this blog.
The below table shows the scaling performance on the ogbn-products dataset of a GraphSAGE model under different partition configurations (1/2/4/8/16).
#Partitions |
|
|
|
|---|---|---|---|
1 |
98s |
47s |
38s |
2 |
45s |
30s |
24s |
4 |
38s |
21s |
16s |
8 |
29s |
14s |
10s |
16 |
22s |
13s |
9s |
Hardware: 2x Intel(R) Xeon(R) Platinum 8360Y CPU @ 2.40GHz, 36 cores, HT On, Turbo On, NUMA 2, Integrated Accelerators Available [used]: DLB 0 [0], DSA 0 [0], IAA 0 [0], QAT 0 [0], Total Memory 256GB (16x16GB DDR4 3200 MT/s [3200 MT/s]), BIOS SE5C620.86B.01.01.0003.2104260124, microcode 0xd000389, 2x Ethernet Controller X710 for 10GbE SFP+, 1x MT28908 Family [ConnectX-6], 1x 894.3G INTEL SSDSC2KG96, Rocky Linux 8.8 (Green Obsidian), 4.18.0-477.21.1.el8_8.x86_64
Software: Python 3.9, PyTorch 2.1, PyG 2.5,
pyg-lib0.4.0